
【重点】深度学习基本概念
摘要:机器学习专注于从数据中开发自动学习算法,模型相对简单;深度学习是其分支,适合处理复杂数据,模型通常更深。感知机是二元线性分类器,涉及输入层、权重、偏置等。梯度消失和梯度爆炸分别导致神经网络学习停滞或失控。前向传播计算输出,反向传播基于梯度更新参数。模型参数是自动学习的,超参数则需手动设置。线性函数具备叠加和齐次性,非线性函数不满足此特性。激活函数有无饱和性之分,影响导数变化。
1 机器学习 vs. 深度学习
- 机器学习
- 概念层次:是人工智能的一部分,专注于开发能够从数据中自动学习和改进的算法。
- 模型结构:模型简单,涉及较少的计算层次。
- 深度学习
- 概念层次:是机器学习的一个分支,擅长处理复杂的、非结构化的数据,例如自然语言和视频。
- 模型结构:模型复杂,通常包含数十、数百,甚至上千层,依赖于强大的计算能力(如GPU)进行训练。
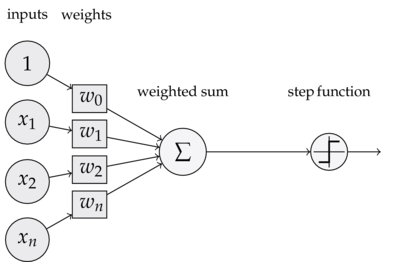
2 感知机
- 一句话
- 二元线性分类器。
- 基本结构
- 输入层、权重w、偏置b、激活函数、输出层。
3 梯度消失 vs. 梯度爆炸
- 梯度消失
- 在反向传播时,梯度随着层数增加而逐渐变小,最后接近于零。最终导致前面几层的权重几乎不更新,神经网络无法有效学习。
- 梯度爆炸
- 在反向传播时,梯度随着层数增加而逐渐变大,最后变得非常大。最终导致权重更新过大甚至数值溢出,神经网络无法收敛。
4 前向传播 vs. 反向传播
- 前向传播
- 将数据传入网络输入层,接下来经过多个隐藏层,每个隐藏层利用权重、偏置和激活函数计算结果,最终得到输出。
- 反向传播
- 首先利用输出与真实标签计算损失。
- 通过链式法则,从输出层开始,逐层计算损失函数对每个参数的偏导数(即梯度)。
- 最后使用梯度下降等优化算法,根据梯度更新每一层的权重和偏置。


5 模型参数 vs. 超参数
- 模型参数
- 在训练过程中通过数据自动学习得到,例如权重和偏置。
- 超参数
- 训练之前手动设置的,不会在训练过程中更新,例如学习率、批量大小、激活函数等。
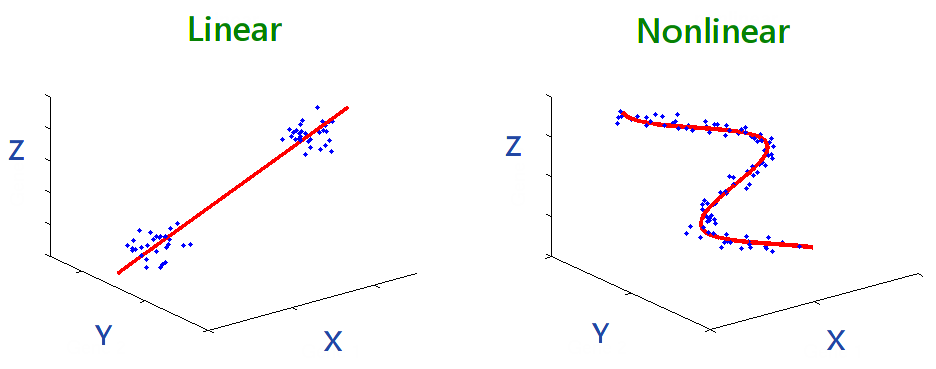
6 线性函数 vs. 非线性函数
- 线性函数
- 满足叠加性和齐次性:f(a+b)=f(a)+f(b) 和 f(cx)=cf(x),c是一个常数。因此,线性函数的图像是一条直线,具有恒定的斜率。
- 非线性函数
- 如果一个函数不满足上述线性特性,它就是非线性的。
7 激活函数饱和性
- 无饱和性
- 函数导数正常。
- 例如:Relu右侧。
- 软饱和性
- 在激活函数的某些范围内,函数导数为接近零的小数。
- 例如:Sigmoid、Softmax、Tanh。
- 硬饱和性
- 在激活函数的某些范围内,函数导数为零,输出完全饱和。
- 例如:Relu左侧。
版权声明:
作者:Zhang, Hongxing
链接:http://zhx.info/archives/131
来源:张鸿兴的学习历程
文章版权归作者所有,未经允许请勿转载。
THE END
二维码