
【重点】RNN – 循环神经网络
摘要:RNN(循环神经网络)是一种能处理序列数据的神经网络,可以利用先前的输入信息来进行预测当前时刻的值。

1 模型原理
1.1 超参数
input_size:input_size是指每个时间步长输入的特征维度。在处理序列数据时,每个时间步可能包含多个特征。例如,在一个天气预测问题中,每天的输入可能包含温度、湿度、风速等多个特征。这些特征的数量就是input_size。sequence_length:sequence_length决定了模型会处理多少个时间步的数据。假设我们有一个每日温度数据集,并且我们希望使用过去7天的温度来预测第8天的温度。每个输入序列的长度就是7,即sequence_length = 7。
1.2 输入
- 序列数据:
(batch_size, sequence_length, input_size) - 隐藏状态:默认全0,
(num_layers * num_directions, batch_size, hidden_size)
1.3 计算
对于每一个时间步:
- 隐藏状态:先将当前输入
xt和上一个隐藏状态h(t-1)拼接后乘上权重,套一个sigmoid。 - 该时间步的输出: 将刚刚算出来的隐藏状态乘上权重,套一个sigmoid。
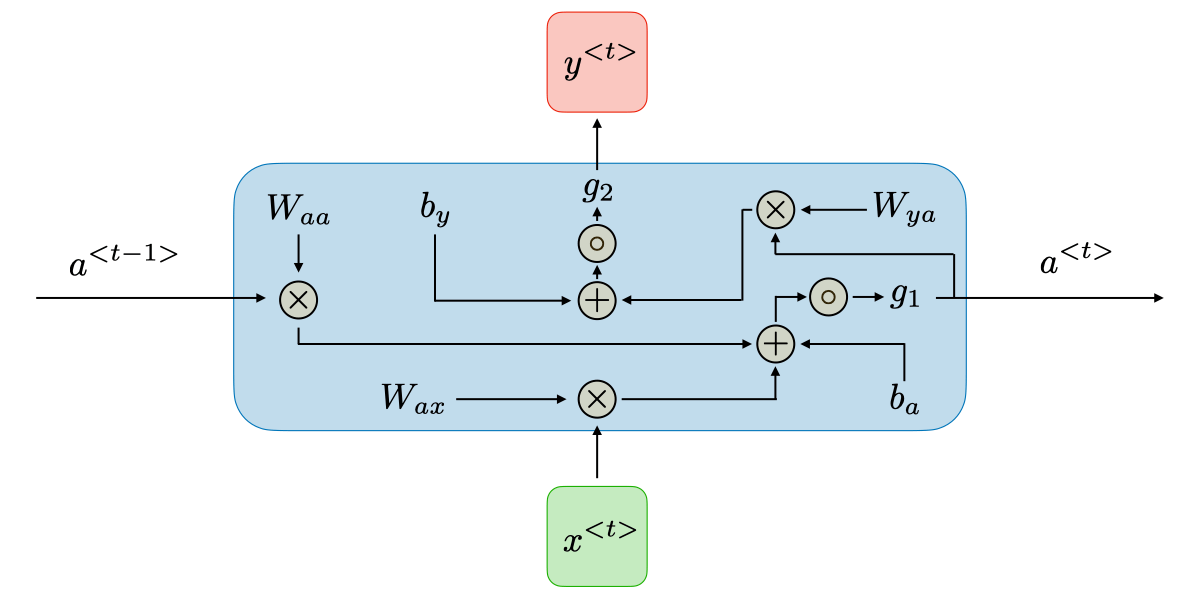
1.4 输出
序列数据:(batch_size, sequence_length, hidden_size)
1.5 后处理
使用 out = self.fc(out[:, -1, :]) 获得最终输出结果。
out[:, -1, :]:提取最后一个时间步的隐藏状态,形状为(batch_size, hidden_size)。self.fc:将隐藏状态的最后一个时间步映射为输出,形状为(batch_size, output_size)。
2 Q&A
2.1 hidden_size的意义
hidden_size 的意义是什么,为什么不能直接用 input_size ?
input_size是输入特征的数量,由输入数据的特征决定。hidden_size是隐藏状态的特征数量,用于控制网络的表示能力和容量。- 如果使用
input_size代替hidden_size,模型的容量和复杂度将受到限制,尤其当input_size很小时。
2.2 tanh的意义
为什么候选单元状态、隐藏状态的计算使用了 tanh ?
tanh将输出映射为[-1, 1],候选单元状态可以具有正负值,提高模型表示能力。
2.3 权重的意义
为什么在计算各单元时需要用到权重?
- 提高模型表示能力。
- 改变矩阵形状。拼接后矩阵形状为
(batch_size, input_size + hidden_size),乘上权重后的形状为(batch_size, hidden_size)。
2.4 代码中的偏置
为什么在“手动实现”的代码中只有 w 没有 b 。
- 因为
nn.Linear已经内置了b。
2.5 Loss
为什么RNN训练的时候Loss波动很大?
- 因为RNN每一步的输出不仅依赖当前步的网络,还依赖于之前若干步的网络状态。梯度时大时小,同时learning rate没法个性化的调整,导致RNN在训练的时候Loss波动很大。
- 解决方法:详见梯度消失/梯度爆炸部分。
2.6 梯度消失
RNN中为什么会出现梯度消失?
sigmoid函数的导数范围是(0,0.25],tanh函数的导数范围是(0,1],他们的导数最大都不大于1 。- RNN的激活函数是嵌套在里面的,求导后会导致激活函数导数的累乘,也就是许多小数的累乘,最后梯度越来越小直到接近于0。
2.7 RNNs vs. ANN
RNNs训练和传统ANN训练异同点?
- 相同点
- 反向传播:都使用反向传播算法来计算梯度并更新权重。
- 激活函数:都使用激活函数(如ReLU、sigmoid、tanh等)来引入非线性,帮助模型捕捉复杂的模式。
- 不同点
- 网络参数:RNNs网络参数
W,U,V是共享的(不断更新的是隐藏状态),而传统神经网络各层参数间没有直接联系。 - 梯度计算:RNN使用“反向传播通过时间”(BPTT, Backpropagation Through Time)来计算梯度,即展开整个时间序列逐步计算每个时间步的梯度,因为每一步的输出不仅依赖当前步的网络,还依赖于之前若干步的网络状态。传统的ANN使用标准的反向传播算法,在单个前向传播和后向传播过程中计算梯度。
- 网络参数:RNNs网络参数
3 代码实现
3.1 手动实现
import torch
import torch.nn as nn
class SimpleRNNCell(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(SimpleRNNCell, self).__init__()
self.input_size = input_size
self.hidden_size = hidden_size
self.output_size = output_size
# 定义输入到隐藏状态的线性层
self.i2h = nn.Linear(input_size + hidden_size, hidden_size)
# 定义隐藏状态到输出的线性层
self.h2o = nn.Linear(hidden_size, output_size)
def forward(self, x, h_prev):
# 将当前输入 x 和前一时间步的隐藏状态 h_prev 拼接在一起
combined = torch.cat((x, h_prev), 1)
# 计算当前时间步的隐藏状态
h_t = torch.tanh(self.i2h(combined))
# 计算当前时间步的输出
o_t = self.h2o(h_t)
return h_t, o_t
# 超参数
input_size = 10 # 输入特征的维度
hidden_size = 20 # 隐藏状态的维度
output_size = 5 # 输出的维度
# 实例化RNN单元
rnn_cell = SimpleRNNCell(input_size, hidden_size, output_size)
# 输入数据
batch_size = 3
x = torch.randn(batch_size, input_size) # 当前时间步的输入
h_prev = torch.zeros(batch_size, hidden_size) # 前一时间步的隐藏状态
# 前向传播
h_t, o_t = rnn_cell(x, h_prev)
print("Hidden state:", h_t)
print("Output:", o_t)Copy
3.2 调用库函数
import torch
import torch.nn as nn
class RNNModel(nn.Module):
def __init__(self, input_size, hidden_size, output_size, num_layers):
super(RNNModel, self).__init__()
self.hidden_size = hidden_size
self.num_layers = num_layers
self.rnn = nn.RNN(input_size, hidden_size, num_layers, batch_first=True)
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x):
# 手动初始化隐藏状态
# h0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size).to(x.device)
# out, _ = self.rnn(x, h0)
# 使用默认隐藏状态(全0)
out, _ = self.rnn(x)
# 解码最后一个时间步的隐状态
out = self.fc(out[:, -1, :])
return out
input_size = 10
hidden_size = 20
output_size = 1
num_layers = 2
# 实例化模型、损失函数和优化器
model = RNNModel(input_size, hidden_size, output_size, num_layers)
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
# 示例输入 (batch_size, sequence_length, input_size)x = torch.randn(5, 3, input_size)
y = torch.randn(5, output_size)
# 前向传播
output = model(x)
loss = criterion(output, y)
print(f'Output: {output}')
print(f'Loss: {loss.item()}')
# 反向传播和优化
optimizer.zero_grad()
loss.backward()
optimizer.step()版权声明:
作者:Zhang, Hongxing
链接:http://zhx.info/archives/126
来源:张鸿兴的学习历程
文章版权归作者所有,未经允许请勿转载。
THE END
二维码