
【重点】深度学习常见问题
摘要:本篇博客介绍了神经网络训练中的关键概念和技巧,涵盖了梯度下降算法、梯度消失问题的解决方法、激活函数的选择与比较、优化参数的策略。此外,文章还深入探讨了模型的正则化、权重初始化和学习率调整的方式,并解释了批归一化、层归一化等技术的应用场景。
1 梯度下降步骤
- 梯度 = 损失J对θ求导。从输出层开始应用链式法则,对每一层求梯度。
- 下降距离 = α * 梯度。
- 判断是否终止:如果所有θ的下降距离都小于λ,则算法终止。
- 更新θ:θ = θ - 下降距离。

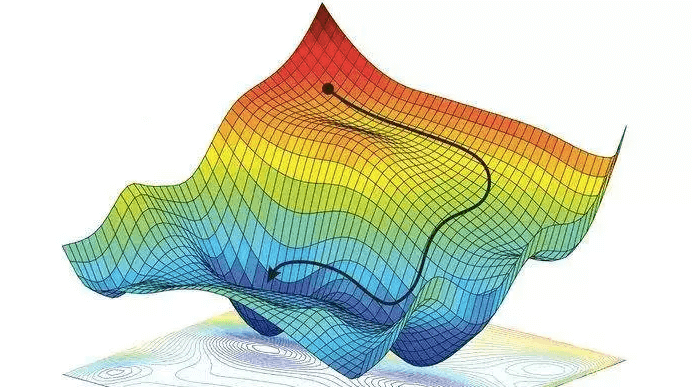
2 梯度下降方法分类
- 随机梯度下降:用一个样本来梯度下降。训练速度快,算法复杂度高。仅仅用一个样本决定梯度方向,导致解有可能不是全局最优。
- 批量梯度下降:用所有数据来梯度下降。在样本量很大时训练速度慢,算法复杂度高。
- Mini-Batch 小批量梯度下降:用其中的n (1<n<m) 个子样本来迭代。
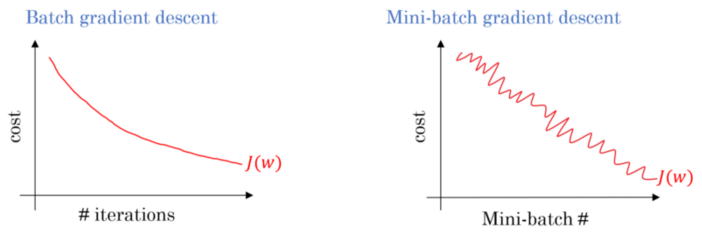
3 如何解决梯度消失/爆炸问题
- 初始化
- 权重初始化:使用合适的权重初始化方法,例如He初始化和Xavier初始化。
- 模型结构
- 传播结构:使用更好的模型,例如将RNN替换为LSTM。
- 输入归一化:使用BN层,对每一层的输入进行归一化处理。
- 残差连接:使用ResNet,直接将输入加到输出上。
- 激活函数:使用ReLU或其变体,因为这些激活函数在输入较大或较小的时候不会像Sigmoid或Tanh那样导致梯度消失。
- 参数优化
- 优化算法:使用能够自适应学习率的算法,例如Adam、RMSprop。
- 梯度裁剪:对梯度进行裁剪,防止梯度过大或过小。
4 如何寻找超参数的最优值
- 人工调优:根据经验直觉选择参数,一直迭代。
- 网格搜索:让计算机尝试在一定范围内均匀分布的一组值。
- 随机搜索:让计算机随机挑选一组值。
- 贝叶斯优化。
5 为什么需要非线性激活函数
- 引入非线性特性
- 如果都使用线性激活函数,无论网络的层数有多深,最终输出都是输入的线性组合。
- 引入非线性激活函数后,神经网络可以在输入和输出之间建立非线性关系,提高模型表示能力。
- 控制输出范围
- Sigmoid将输出限制在0和1之间,Tanh将输出限制在-1到1之间),有助于归一化处理、防止数值上溢下溢。
6 常见激活函数
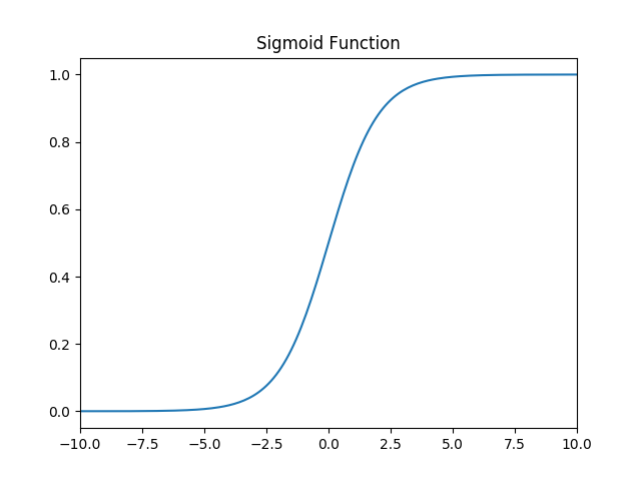
6.1 Sigmoid
- 值域:
(0, 1) - 左右侧具有软饱和性。
σ(x)=11+e−x
6.2 Softmax
- 每一个y的值域为
(0, 1),取最大概率对应的标签为预测值。 - 左右侧具有软饱和性。
softmax(xi)=exi∑j=1nexj
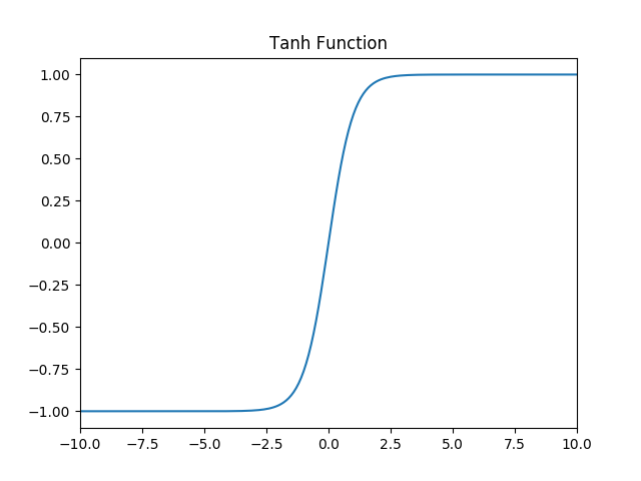
6.3 Tanh
- 值域:
(-1, 1) - 左右侧具有软饱和性。
tanh(x)=ex−e−xex+e−x
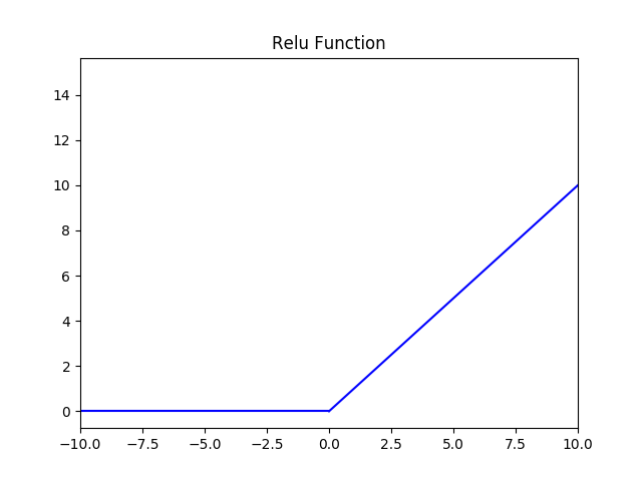
6.4 Relu
- 值域:
[0, +∞) - 左侧硬饱和性,右侧无饱和性。
ReLU(x)=max(0,x)
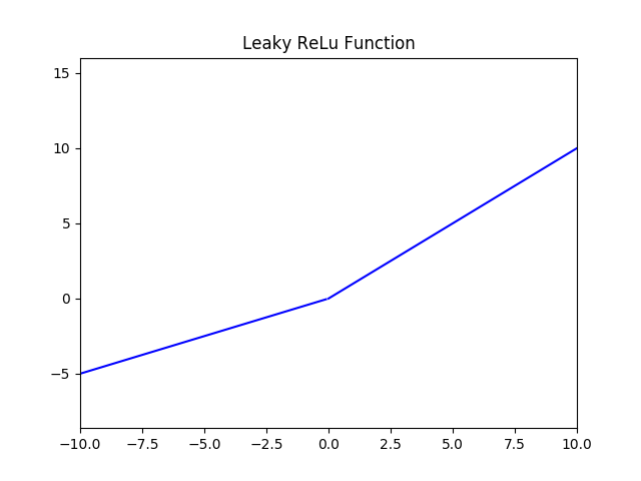
6.5 Leak Relu
- 值域:
(-∞, +∞) - 左右侧无饱和性。
Leaky ReLU(x)={xif x≥0αxif x<0
6.6 PReLU
- PReLU:Parametric Relu,α为可学习的参数。
- 值域:
(-∞, +∞) - 左右侧无饱和性。
PReLU(x)={xif x≥0αxif x<0
6.7 RReLU
- RReLU:Randomized Relu,α是一个在训练过程中随机选取的值,α∈[l,u],l和u为超参数。
- 值域:
(-∞, +∞) - 左右侧无饱和性。
RReLU(x)={xif x≥0αxif x<0
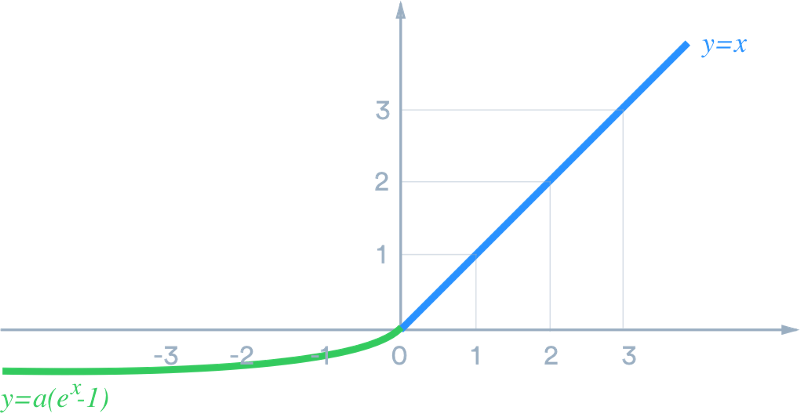
6.8 ELU
- 值域:
(-α, +∞),α为可学习的参数。 - 左侧软饱和性,右侧无饱和性。
- 与 ReLU 不同,ELU在负数部分仍有梯度,使梯度的平均值接近零,收敛速度更快。
ELU(x)={xif x≥0α(ex−1)if x<0
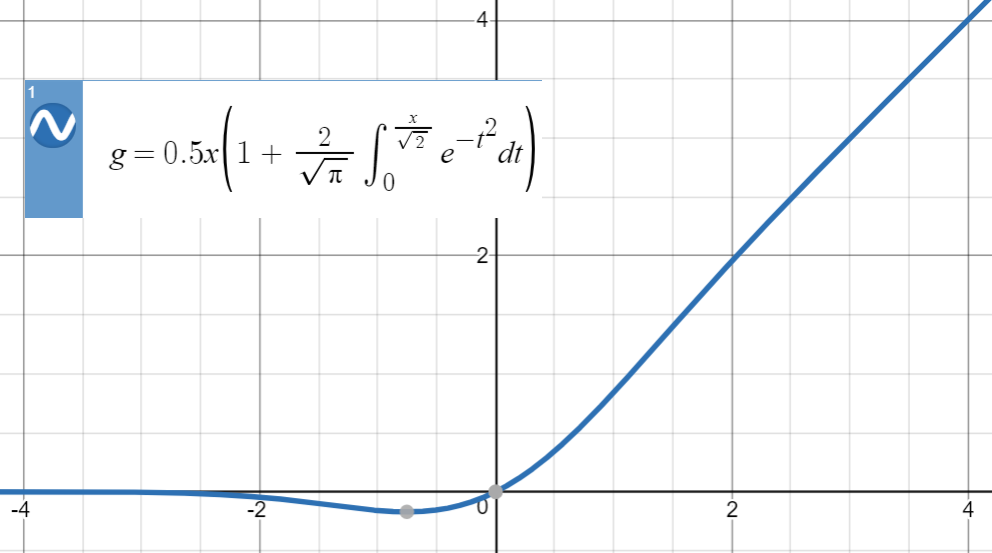
6.9 Gelu
- 与 ReLU 不同,GELU 对输入值进行平滑处理,在负数部分,当负数的绝对值没那么大时,会给予一定的梯度。但计算开销大。
- Φ 为正态分布的累积分布函数。
- 左侧硬饱和性,右侧无饱和性。
GELU(x)=x⋅Φ(x)
7 激活函数的性质
- 非线性
- 可微性:导数存在且连续,用于支持梯度下降等优化算法。
- 单调性:有助于确定梯度在反向传播中的传递方向,减少不稳定性。
8 如何选择激活函数
- 默认使用ReLu。
- 如果遇到了一些死的神经元,可以使用leaky relu或Gelu。
- 如果需要对称映射,可以使用tanh。
- 如果是二分类问题,可以使用sigmoid。
- 如果是多分类问题,可以使用softmax。
- 如果是回归问题的最后一层,可以使用线性激活函数。
9 为什么tanh收敛速度比sigmoid快
tanh导数取值为 (0, 1) ,sigmoid导数取值为 (0, 1/4] ,tanh梯度消失的问题比sigmoid轻。
10 Relu的优点
- 缓解梯度消失
- relu在正值区域的导数为1。sigmoid和tanh正负饱和区的梯度都会接近于0。但relu进入负半区的时候梯度为0,如果希望解决这个问题可以使用Leaky ReLu。
- 计算简单高效
- relu只需要判断输入是否大于零,然后输出相应的值。sigmoid和tanh需要进行复杂运算。
11 如何理解 Relu< 0 时是非线性激活函数
- Relu是一个分段函数,它的非线性表现在定义域被分成了两个不同的区间: x≥0的线性区间、x<0的常量区间。
- 从整体来看,它是非线性的。
12 Softmax自然指数的意义
- 简化导数计算:ex的导数是它本身。
- 简化损失函数中的log计算:ex可以和log运算抵消。
- 指数增长的敏感性:指数可以放大输入值之间的差异,让预测更加明显。
13 初始值归一化的优点
-> 缩放特征尺度
- 提高训练速度
- 如果特征的尺度差异很大,梯度下降算法可能会在某些维度上更新过快,而在其他维度上更新过慢,导致收敛变慢(之字型路线)。归一化后会垂直于等高线走。
- 提高特征工程效果
- 不会过度依赖于特定特征的尺度。
- 缓解过拟合
- 减少模型对训练数据原始特征分布的过拟合风险,使在新数据上的表现更加稳定。
14 常见归一化方法
- Z-score归一化:x′=x−μδ
- 最大-最小归一化:x′=x−xminxmax−xmin
15 批归一化BN
- 计算
- x' = (x-μ)/δ
- y = γx' + β,γ和β为可学习的参数
- 优点
- 初始值归一化的优点
- 正则化效果:每个小批量数据的均值和方差的随机波动会对参数更新产生噪声,类似dropout。
- 减少了人为选择参数:在某些情况下可以取消 dropout 和 L2 正则项参数,或者采取更小的 L2 正则项参数。
- 减少了对学习率的要求:可以使用初始较大或较小的学习率,也能快速收敛。
16 WN权重归一化 vs. BN
- 优点
- 不依赖于mini batch:RNN序列是变长的,无法使用BN。即使填充,填充值对均值和方差影响较大。
- 不需要额外的存储空间来保存 mini batch 的均值和方差:RNN是基于时间步计算的,使用BN需要保存每个时间步的均值和方差,效率低且占内存。
- 缺点
- 无法将每层的输出控制在某个范围。
17 LN层归一化 vs. BN
- BN:对一批内所有样本的同一个特征进行归一化。
- LN:对同一个样本的所有特征进行归一化。
- NLP无法使用BN:NLP序列是变长的。即使填充,填充值对均值和方差影响较大。
18 Fine-tuning类型
- 不训练,只预测。
- 只训练最后的分类层。
- 完全训练。
19 权重初始化
- 不能全0
- 每个神经元在每一层的输出和梯度将完全相同。
- 这会导致每个神经元的参数在训练过程中以相同的方式更新,学习相同的特征。
- 随机初始化
- N(0, t):均值为0、方差为t的高斯分布。
- He 初始化
- N(0, 2/n):均值为0、方差为2/n的高斯分布,n为输入单元的数量。
- Xavier 初始化
(-limit, limit)中的均匀分布。- limit = np.sqrt(6 / (in_dim + out_dim))
- 校准方差
- 目的
- 使输入与输出的方差保持一致。
- 方法
- 乘以1/sqrt(n)。
0.01 * np.random.randn(n) / sqrt(n),n为向量长度。
- 乘以1/sqrt(n)。
- 原理
- n⋅σw2⋅σx2=σx2
- σw2=1n
- 目的
20 偏置初始化
- 默认:全0。
- 有时:小的常数值,如 0.01。
21 学习率
- 意义
- 每次迭代时调整权重的幅度。
- 常用参数
- learning_rate:初始学习率
- decay_steps:衰减步数
- decay_rate:衰减率
- alpha:最小学习率
- 衰减方式
- 分段常数衰减
- 指数衰减
- 自然指数衰减
- 多项式衰减
- 余弦衰减

22 正则化
- L1正则化
- 公式:在损失函数中添加模型权重的绝对值之和。
- 效果:将一些权重推向零。
- Loss=Lossoriginal+λ∑i|wi|
- L2正则化
- 公式:在损失函数中添加模型权重的平方和。
- 效果:让模型的权重尽可能小,但不会使其变为零。
- Loss=Lossoriginal+λ∑iwi2
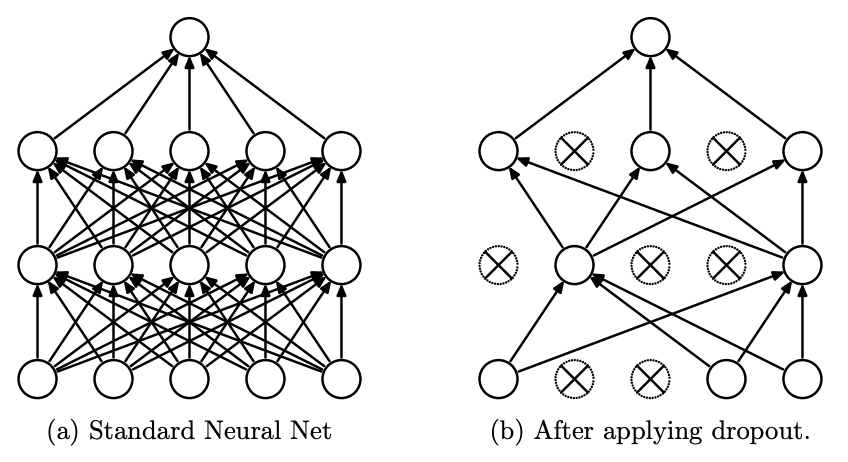
- Dropout
- 效果:随机丢弃一定比例的神经元,减少模型对某些特定神经元的依赖。(Dropout率为丢弃率)
- 参数选择:调试阶段关闭Dropout。训练阶段Dropout默认为0.5;输入层使用0.2,因为如果Dropout太高会丢弃过多的输入特征。
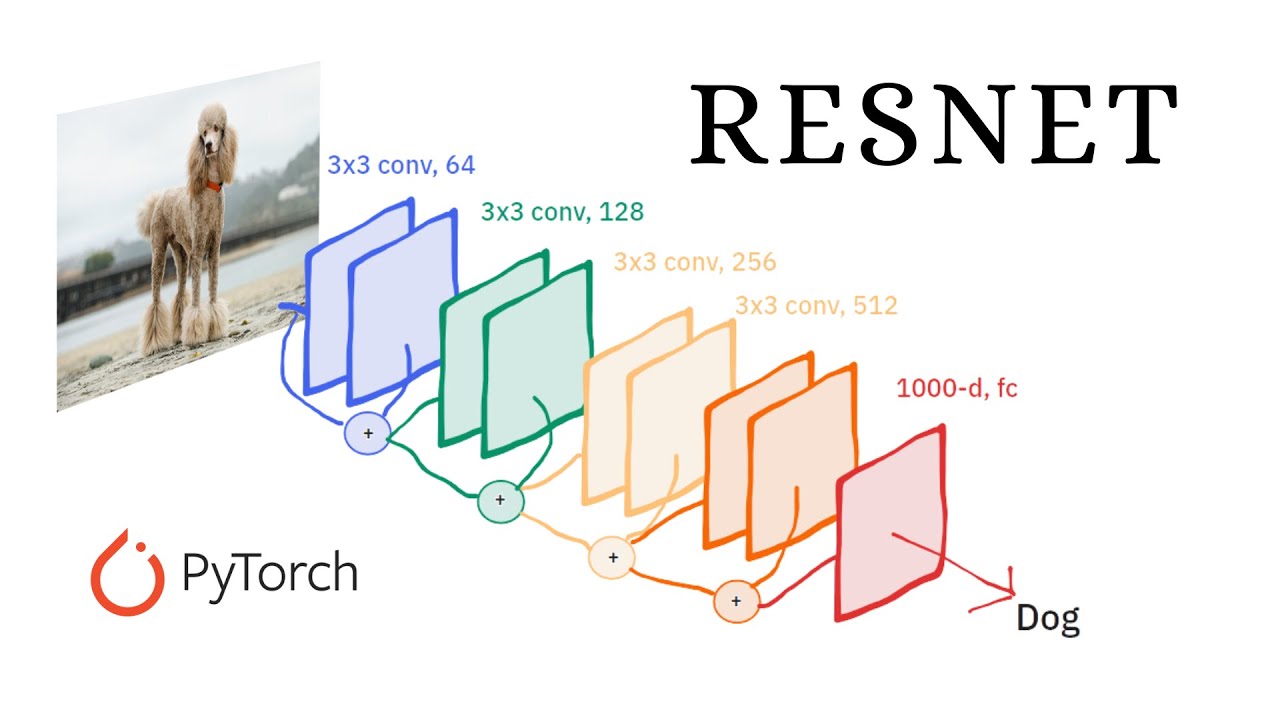
23 ResNet
- 在神经网络中引入跳跃连接。
- Output=Activation(F(x)+x)
24 Torch如何处理文本数据
- 预处理:对原始数据进行预处理,进行分词,繁体字转化,半角符号转化。
- 构建词汇表:记录各个词汇的词频,过滤低词频词汇,简历
word2index的映射表保存起来,需要注意pad和unk符号。 - 转为tensor:把数据(训练/测试/dev,使用参数进行控制)转化为对应的index,按照最大长度进行补全,并转化为tensor。
- 构造数据集:制造自己的数据集类,改写关键部位,一般是get_item这里,以便被dataloder处理。
版权声明:
作者:Zhang, Hongxing
链接:http://zhx.info/archives/130
来源:张鸿兴的学习历程
文章版权归作者所有,未经允许请勿转载。
THE END
二维码