
【吴恩达机器学习】Linear regression
fdsf
1 Loss function
loss function定义每个样本的残差

1 Cost function
1.1 MSE
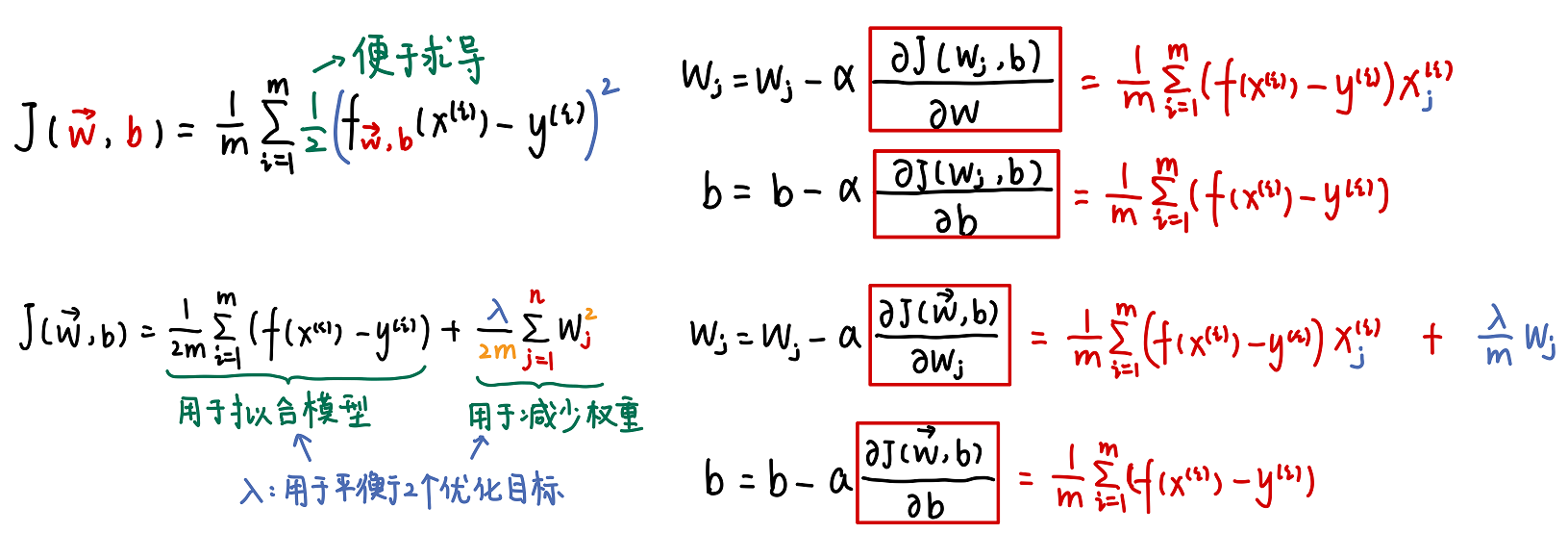
1.1.1 J(w, x)
在线性回归中,cost function使用了均方误差 MeanSquraedError(MSE)。
J是对于所采用的的w和b来说的,每个w和b对应一个J。在后续的的梯度下降中,降低J就是为了选取最适合的w和b。
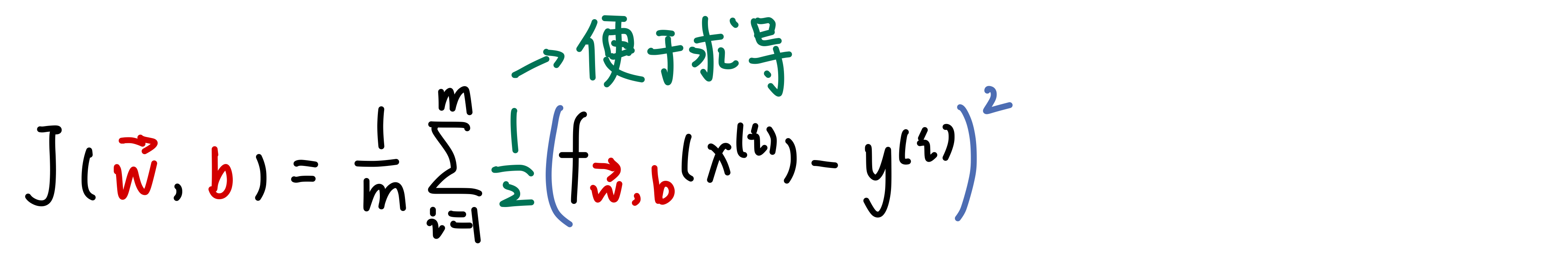
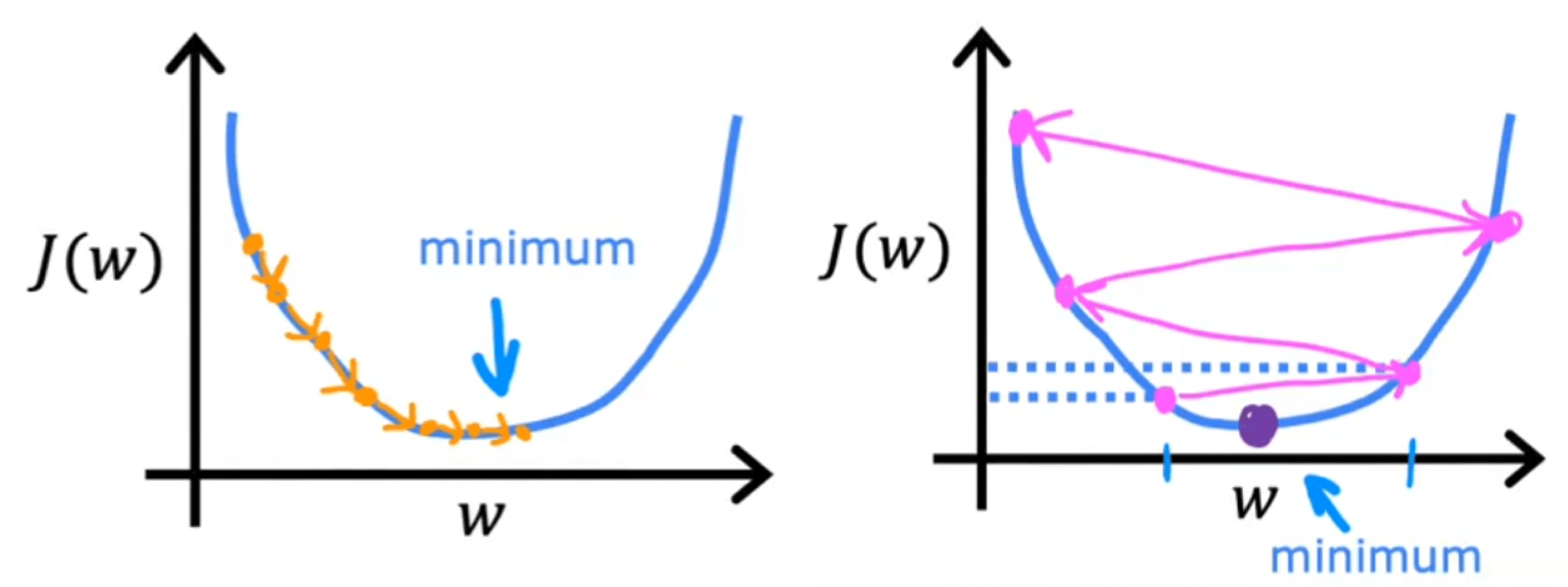
1.1.2 Gradient descend
(1)梯度下降需要同时更新w1, w2, …, wn和b,注意:每个w是分开计算的,不是同时计算整个w向量
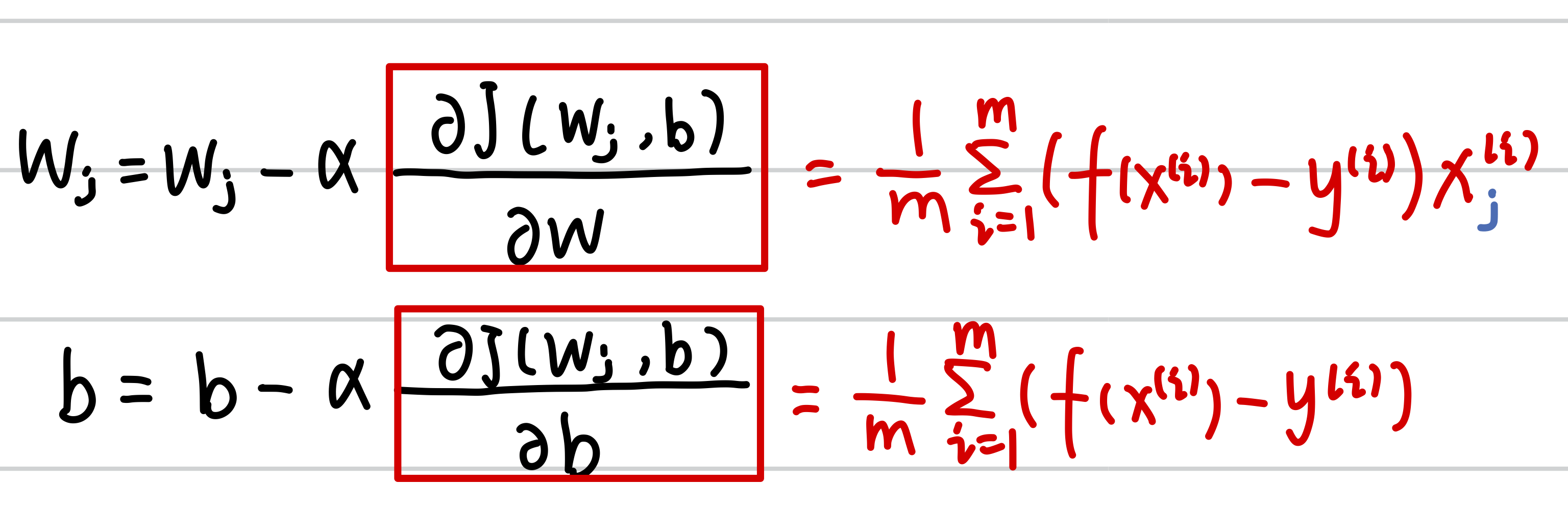
(2)偏导控制方向:当斜率>0时,向左走;当斜率<0时,向右走;当斜率=0时,不再变动。(斜率不能控制步伐,当斜率为负数时,斜率越高,坡越缓)
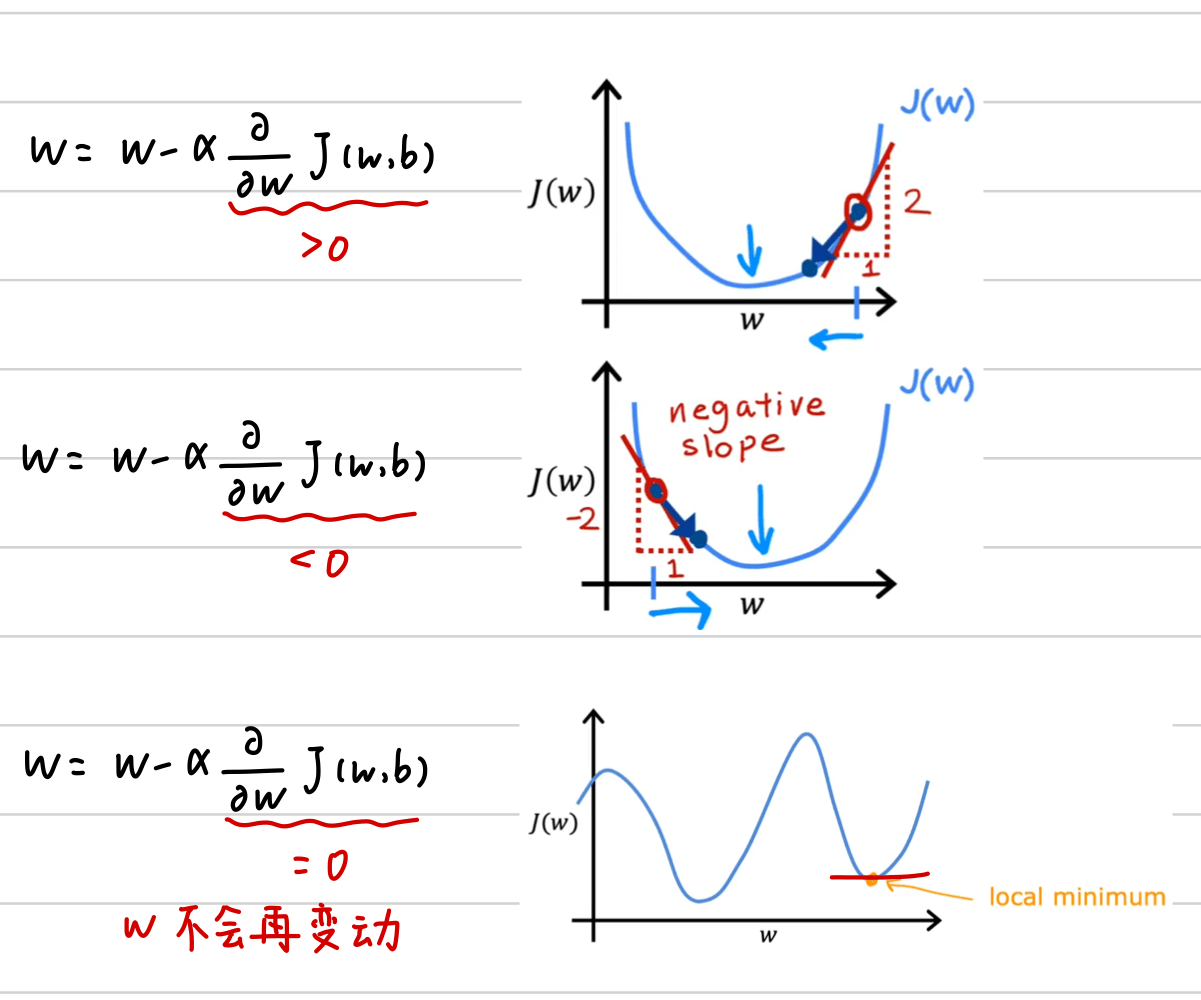
(3)学习率控制步伐:a越大步伐越大,a过大时无法收敛,a过小时梯度下降速度太慢。
(4)偏导的推导过程:

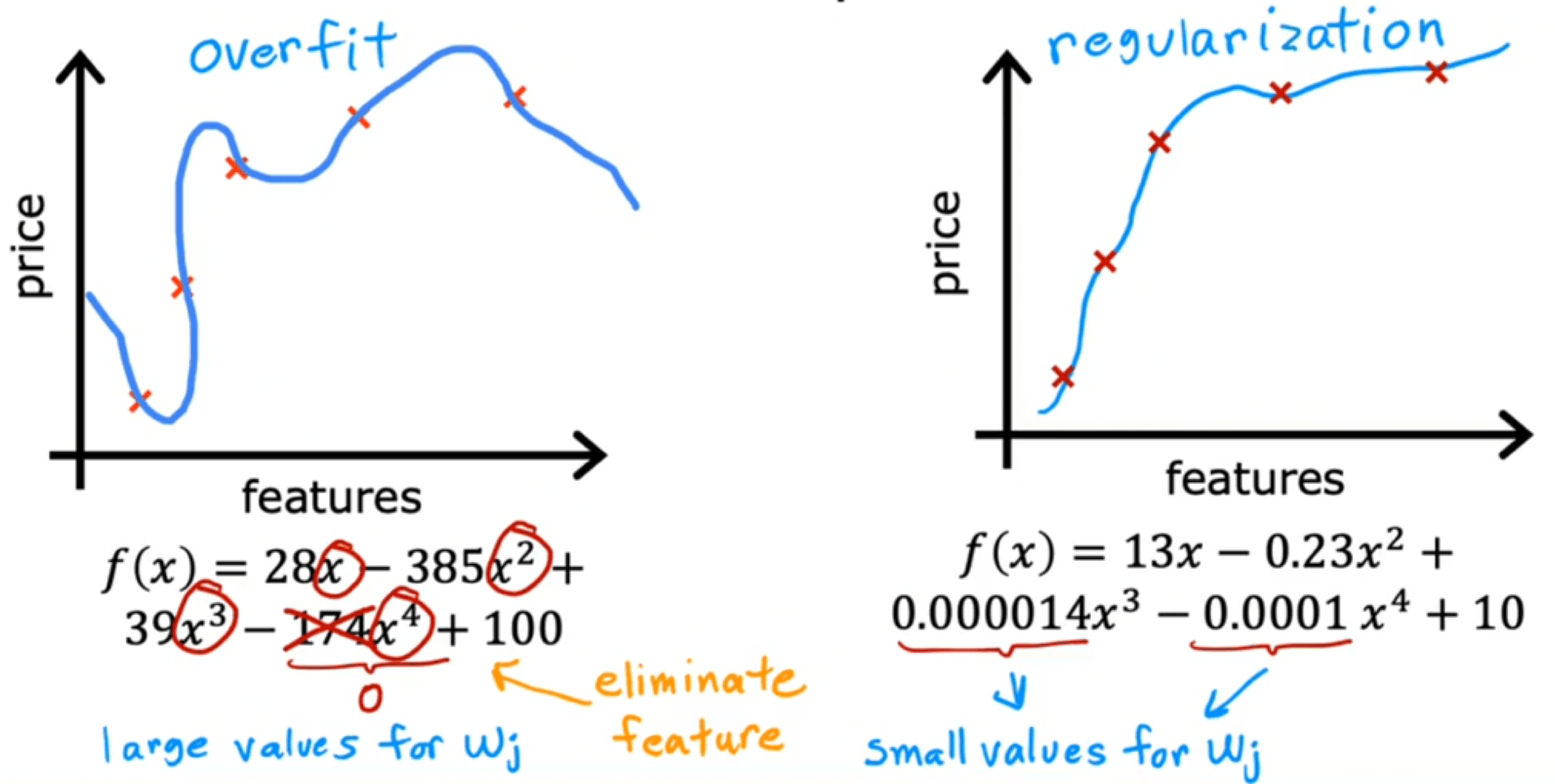
1.2 正则化后的MSE
1.2.1 J(w, x)
(1)正则化的目的:防止权重过大(1.避免过拟合,过高次项的w经过正则化后会趋近于0;2.避免某个w过大,该变量一点点的变动都会对模型产生很大的影响)
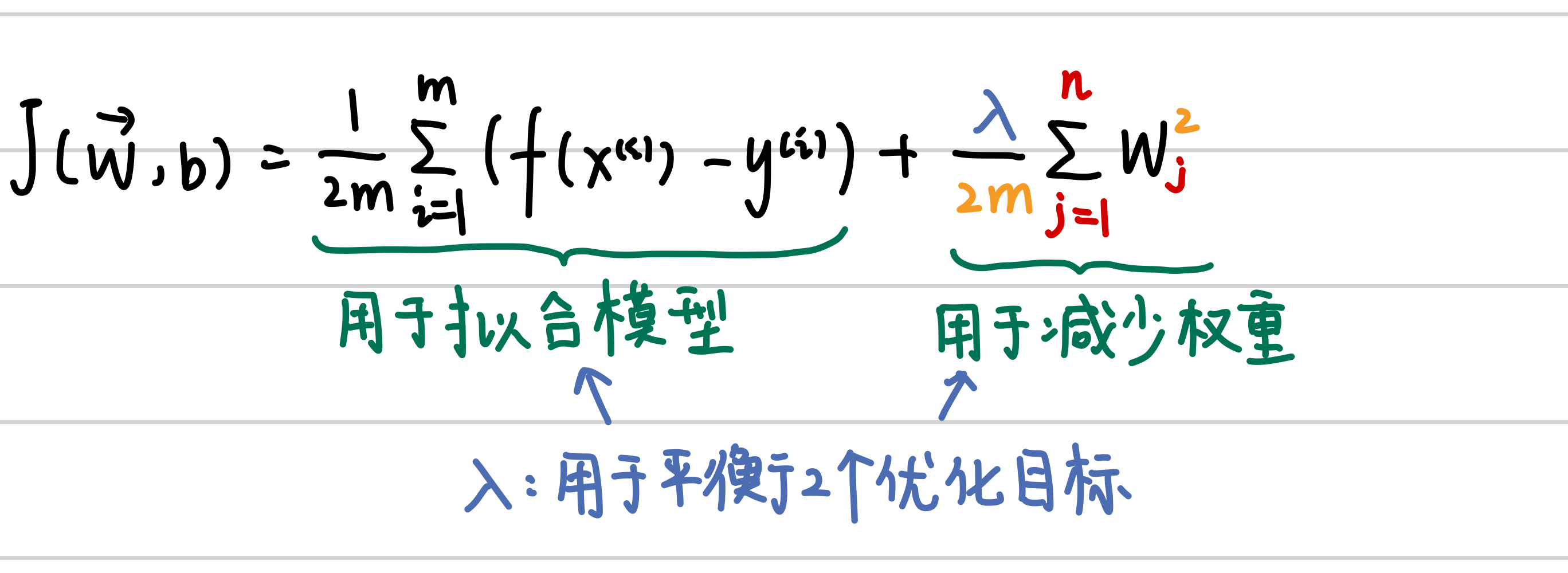
(2)公式分为2部分:
①cost function的思想:最小化loss、减小w
②凑数:w加上平方是因为便于求导,正则项不除n而除2m是因为便于后续梯度下降凑数(详见3.2.2)
cost function是一种思想,我们希望最小化什么数学项,就将该数学项加入cost function,并赋予各种目标的权重(λ)。
1.2.2 Gradient descend
(1)梯度下降公式本质上是一样的,只不过因为J(x)变了,对J(x)的偏导变了,所以计算过程有所不同。
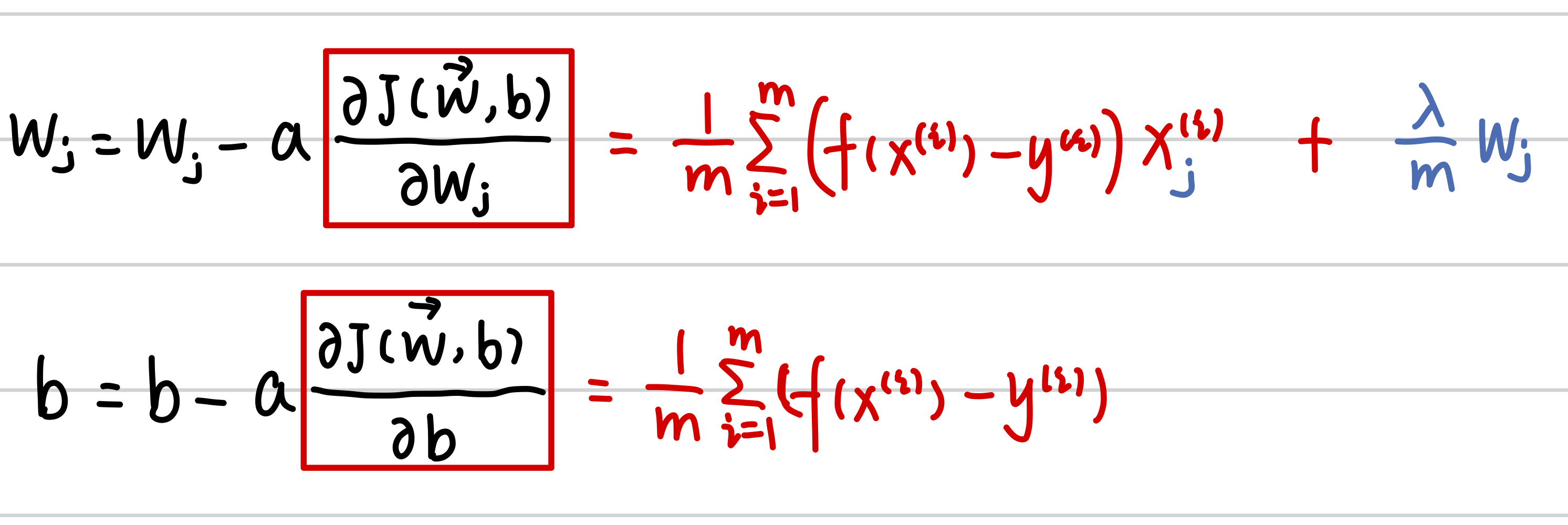
(2)正则化在梯度下降中的数学意义:让wj乘一个趋近于1(<1)的数而凑的(这也是正则项不除n而除m的原因),在每次迭代中减小w值。

(3)偏导的推导过程:

版权声明:
作者:Zhang, Hongxing
链接:http://zhx.info/archives/112
来源:张鸿兴的学习历程
文章版权归作者所有,未经允许请勿转载。